Milestone
ACHIEVEMENTS
The project goes well but there are some challenges. So far, we have completed two GBDT parallel implementations (node parallel and feature parallel) with Open MP and collected some experiment results. We are now working on the third Open MP implementation and the MPI implementation of GBDT. The experiment results and the main challenge are talked in the following sections.
RESULTS
Method 1: Node Parallelism
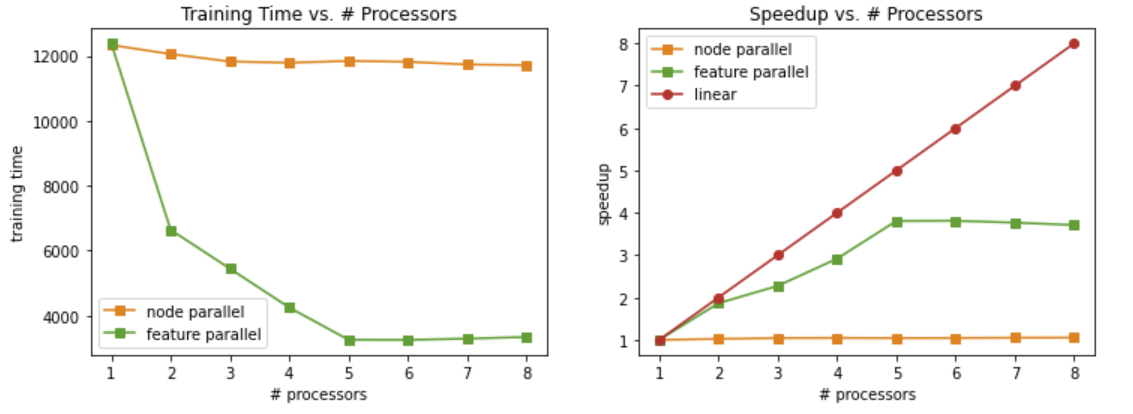
The building of GBDT is a serial process of building many trees. Each tree can only be built in the dependency of precious trees. Therefore, there is no tree-level parallelism. What we can do is to parallelize the building tree process. The first method is to parallelize the sub-tree building, i.e. node-level parallelizem. Since each node is using different data samples to split to children nodes, this process can be done in parallel.
However, there is a main problem of workload imbalance. Different node can have different depth, so the workload of each thread can vary a lot. This imbalance of workload results in speedup that is worse than linear.
Method 2: Feature Parallelism
The second method is feature-level parallelism. To create the children node, we need to enumerate each feature to find the best split. Since features are independent with each other, we can calculate the Gini index for each feature in parallel. After all threads finish, we can gather the results and determine the splitting values. In this method, the workload is balanced because each thread needs to process exactly the same number of instances for one node.
Method 3: Level Parallelism
According to this website, there is another level parallelism. Instead of first looping nodes and then looping features, we can inverse the order and reduce the sorting overhead in each node. The experiement results on the website show that the level parallelism is very powerful which can achieve better performance than previous methods. However, we did not finish this part yet because it took our days to figure out how it really works and we have been debugging for several days. Now we are still not sure we fully understand it and we have emailed the author for further explanation.
CHALLENGE
-
The main challenge we met is to implement the level-parallelism. We have been stuck for days and we think we are on the right track now. We have emailed to the author and we would talk more details. If we cannot finish it before 12/2, we will stop it and continue to work on other parts. If there is time remaining, we will go back to finish this method.
-
Due to the limited time, we may not be able to finish the GPU version of the GBDT, which is our stretch goal according to the proposal.
NEW SCHEDULE
| Date | Task |
|---|---|
| 11/15 | Finish the sequential version |
| 11/17 | Finish the open MP version node-parallelism |
| 11/18 | Finish the open MP version feature-parallelism |
| 11/29 | Stuck with open MP version level-parallelism |
| 12/2 | Finish the open MP version level-parallelism - Qinxin and Jiayuan |
| 12/5 | Finish the mpi version - Jiayuan |
| 12/7 | Finish the experiments and collecting data - Qinxin |
| 12/8 | Finish the poster - Qinxin and Jiayuan |
| 12/9 | The Poster Session |
POSTER SESSION
- Performance tables collected in different versions and different number of nodes used.
- Graphics that show the above performance tables.
- Graphics that show the accuracy/speedup comparison between our implementation and XGBoost.
- Answers to following questions:
- Did we achieve linear speedup? If not, what are the possible reasons?
- Did we observe any workload imbalance in the CPU versions? Is there a way to improve it?
- Compare the results of Open MP and MPI versions. Which one is better for GBDT? Why?